
为什么建议你在React中使用key
key在React中的作用,正确使用可以会带来什么效益

使用React框架开发的前端大家应该都见过这个Warning,大概意思就是 列表(list) 中的 每一个子节点(child) 都必须要有个 唯一的key值。
嗯,没错了,熟悉的配方,熟悉的报错~ 有些小伙伴看到是「Warning」也就置之不理了,有些凭经验反手给元素加上一个 key={index} 属性就迅速解决这个报错了。
那么到底在什么场景下需要添加唯一key及key在React中到底起了什么作用呢?
是什么:
React官方文档中有一篇列表&Key的文档,文中大概讲了以下两点:
- 应当给数组中的每一个元素赋予一个确定的标识
- key值在兄弟节点之间必须唯一
- 尽量避免使用索引值作为key值
1.数组中的每一个元素赋予一个确定的标识
已複製!function ListItem(props) { // 正确!这里不需要指定 key: return <li>{props.value}</li>; } function NumberList(props) { const numbers = props.numbers; const listItems = numbers.map((number) => // 正确!key 应该在数组的上下文中被指定 <ListItem key={number.toString()} value={number} /> ); return ( <ul> {listItems} </ul> ); }
一个好的经验法则 是:在 map() 方法中的元素需要 设置 key 属性 。
2.key值兄弟节点之间必须唯一
数组元素中使用的 key 在其 兄弟节点之间 应该是独一无二的。然而,它们 不需要是全局唯一的 。当我们生成两个不同的数组时,我们可以使用相同的 key 值:
已複製!function Blog(props) { const sidebar = ( <ul> {props.posts.map((post) => <li key={post.id} id={post.id}> {post.title} </li> )} </ul> ); const content = props.posts.map((post) => <div key={post.id} id={post.id}> <h3>{post.title}</h3> <p>{post.content}</p> </div> ); return ( <div> {sidebar} <hr /> {content} </div> ); }
📢需要注意 : key 会传递信息给 React ,但不会传递给你的组件 。如果你的组件中需要使用 key 属性的值,请用其他属性名显式传递这个值,上面在content 及sidebar组件中可以获取到id的值,但获取不到key值。
3.尽量避免使用索引值作为key值
很多次包括我自己及身边开发人员在渲染列表时使用项目的索引作为key值
已複製!all.map((all, index) => ( <All {...all} key={index} /> ));
看起来很优雅,非常的完美,并且消除了Warning(毕竟没有Warning了😂),那么这里会有什么问题吗?
结论就是:有问题,它可能会破坏您的应用程序并显示错误的数据!
key是React唯一用来识别DOM元素的东西。如果将一个项目push到列表或者删除列表中的某一项会发生什么?如果key和之前一样,React会假定该DOM元素是之前一样的组件,显然这个时候就有问题了。举个栗子吧🌰
已複製!export default function App() { const [todo, setTodo] = useState([ "第1项工作","第2项工作"]); const addBegin = () => { setTodo([ `第${todo.length + 1}项工作`, ...todo ]); }; return ( <div className="App"> {todo.map((item, index) => ( <div key={index} className="item"> <div>{item}</div> <input type="text" /> </div> ))} <button onClick={addBegin}>add begin</button> </div> ); }
以上代码在特定场景会出现以下问题
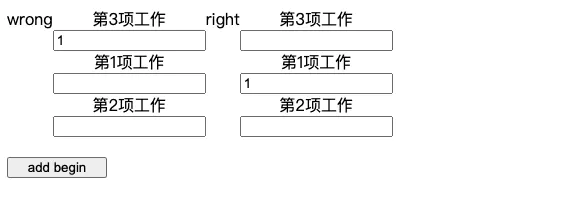
事实证明,当什么都没有传递时,React 会默认使用 索引 作为 键 ,因为它是目前React唯一能做的。此外,它会警告你它是个waring。如果你自己提供它,React 只是认为你知道你在做什么——记住这个例子——可能会导致不可预知的结果。官网提供的使用索引做key的错误列子。
作用:
那么key是如何影响了React的行为呢,这里涉及到React的一个更新流程(也就是我们说的Diff算法)。
为了防止概念混淆,这里再强调下 一个DOM节点在某一时刻最多会有4个节点和他相关。
- current Fiber。如果该DOM节点已在页面中,current Fiber代表该DOM节点对应的Fiber节点。
- workInProgress Fiber。如果该DOM节点将在本次更新中渲染到页面中,workInProgress Fiber代表该DOM节点对应的Fiber节点。
- DOM节点本身。
- JSX对象。即ClassComponent的render方法的返回结果,或FunctionComponent的调用结果。JSX对象中包含描述DOM节点的信息。
Diff算法的本质是对比1和4,生成2。
Diff的瓶颈以及React如何应对
由于Diff操作本身也会带来性能损耗,React文档中提到,即使在最前沿的算法中,将前后两棵树完全比对的算法的复杂程度为 O(n 3 ),其中n是树中元素的数量。 如果在React中使用了该算法,那么展示1000个元素所需要执行的计算量将在十亿的量级范围。这个开销实在是太过高昂。 为了降低算法复杂度,React的diff会预设三个限制:
- 只对同级元素进行Diff。如果一个DOM节点在前后两次更新中跨越了层级,那么React不会尝试复用他。
- 两个不同类型的元素会产生出不同的树。如果元素由div变为p,React会销毁div及其子孙节点,并新建p及其子孙节点。
- 开发者可以通过 key prop来暗示哪些子元素在不同的渲染下能保持稳定。考虑如下例子:
已複製!// 更新前 <div> <p key="ka">ka</p> <h3 key="song">song</h3> </div> // 更新后 <div> <h3 key="song">song</h3> <p key="ka">ka</p> </div>
如果没有key,React会认为div的第一个子节点由p变为h3,第二个子节点由h3变为p。这符合限制2的设定,会销毁并新建。
但是当我们用key指明了节点前后对应关系后,React知道key === "ka"的p在更新后还存在,所以DOM节点可以复用,只是需要交换下顺序。(key在Diff中的作用)。 > 这就是React为了应对算法性能瓶颈做出的三条限制 。
总结
正确的使用key可以帮助 React 在 “diffing” 算法过程中作出更优设计决策,以保证组件更新可预测,且在繁杂业务场景下依然保持应用的高性能,保证当前 UI 与最新的树保持同步。 key值更好的使用方式( 首选 ):
- 使用列表唯一id作为key值 ( key 不需要全局唯一,但在列表中需要保持唯一)
- 使用 Nano ID 库生成唯一字符串
非首选: 有时生成新的 id 是多余的,在一些特殊的场景中我们可以使用 索引值 作为列表的key值:
- 列表和项目是静态的——它们不计算也不改变;
- 列表中的项目没有 ID;
- 该列表 永远不会 重新排序或过滤。
当符合以上三个条件时,你 可以安全地使用索引作为键 。