
前端框架原理概览
前端框架编译原理概览及工作原理
现代前端框架的工作原理
整体来说目前主流的前端框架都符合: UI=f(state)
- 根据自变量变化计算出UI变化。 ^d5ad8a
- 根据UI变化执行具体的宿主环境API。 ^714c1d
编译(AOT vs JIT)
编译的作用
现代前端框架都需要“编译”这一步骤,用于:
- 将“框架中描述的UI”转换为宿主环境可识别的代码;
- 代码转换,比如将ts编译为js,实现polyfill等;
- 执行一些编译时优化;
- 代码打包、压缩;
编译时机
“编译”可以选择两个时机来执行:
- 代码在构建时,被称为 AOT(Ahead Of Time,预编译) ,宿主环境获得的是编译后的代码;
- 代码在宿主环境执行时,被称为 JIT(Just In Time,即时编译) ,代码在宿主环境中编译执行;
AOT 和 JIT的优劣
Tip :由于Angular同时支持两种编译方式,所以下文以Angular来举例。
AOT的优点
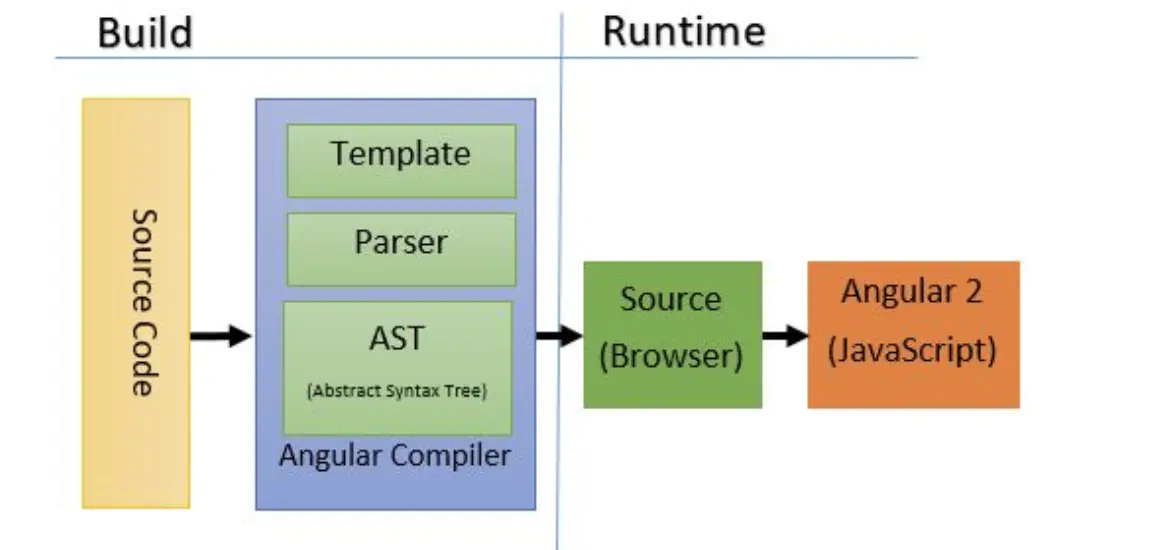
概述 :AOT即在构建期间去编译我们的代码,在浏览器中我们可以直接下载并运行编译后的代码,从 Angular 9 开始编译默认设置为 AOT,下面是使用 AOT 后项目的构建流程:
优点:
- 更快的渲染速度 :使用 AOT 后浏览器会下载应用程序编译后的代码并直接执行,而无需等待先编译应用程序。
- 更小的文件体积 :因为代码已经是编译后的代码,所以在最终的产物中就不需要包含 Angular 编译器,因此他会大大减少应用的负载。
- 更好的安全性 :AOT 在将 HTML 模板和组件提供给客户端之前就将其编译为 JavaScript 文件,由于没有要阅读的模板,也没有危险的客户端 HTML 或 JavaScript 评估。
- 更少的异步请求 :编译器在 Javascript 中内联外部 HTML 模版和 CSS 样式,所以我们不需要单独发送 ajax 请求去请求这些文件。
- 更早的检测代码中的错误 :
已複製!@Component({ selector: "app-root", template: "<h3>{{getName()}}</h3>" }) export class AppComponent { public getName() { return 'xl'; } } // 最终页面会渲染出x1;假如我将 h3 标签中的 getName 改为 getXXX: // 从 - template: "<h3>{{getName()}}</h3>" // 改为 + template: "<h3>{{getXXX()}}</h3>"
如果使用AOT,代码在编译后就会立刻报错:
已複製!ERROR occurs in the template of component AppComponent.
如果使用JIT,代码在编译后不会报错,而是在浏览器中执行报错:
已複製!ERROR TypeError: _co.getXXX is not a function_
JIT的优点
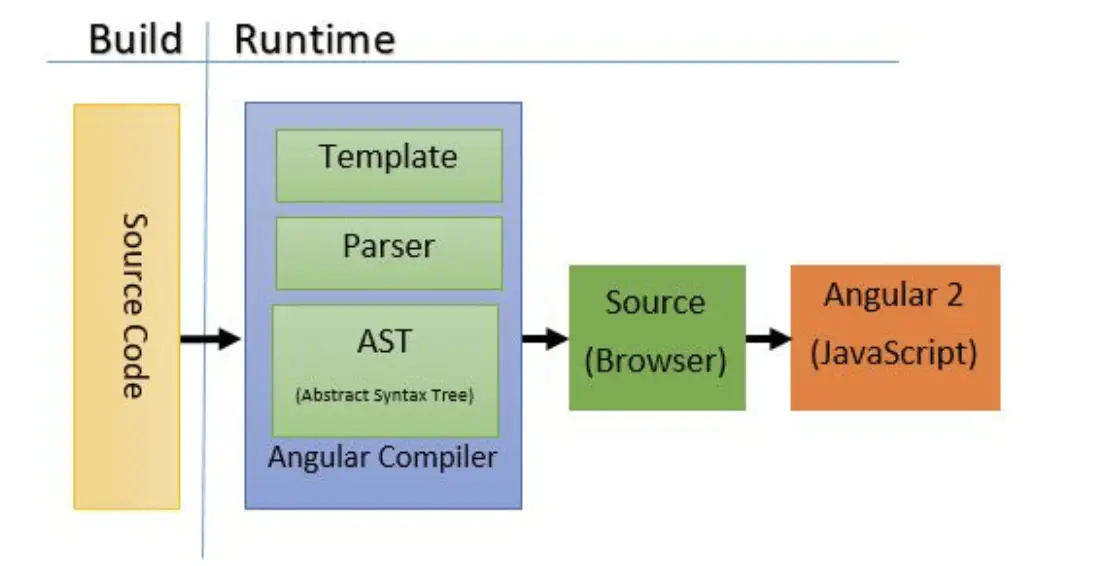
概述: JIT(即时编译) 即在运行时去编译代码,每个文件都是单独编译的,当我们更该代码时不需要再次构建整个项目,下面是该模式下的流程:
 优点:
优点:
-
易于开发调试: 在 JIT 模式下可以生成映射文件,这样便于功能的实现和调试。
-
编译时间短: 因为大多数编译是在浏览器端完成的,因此编译时间会更少,因此对于一些大项目来说如果某些组件大部分时间不使用,那么此时使用 JIT 是最合适的。
-
存储热点代码: 如果某个方法或者代码块执行的特别频繁,那么就会被视为
热点代码,然后 JIT 就会对这部分代码进行编译并存储起来,下次使用时就可以直接从内存中读取。基于以上原因:Angular一般在开发环境中使用JIT,在生成环境中使用AOT。
AOT在JSX中的应用
对于框架而言它主要是帮我们做了两件事:[[#现代前端框架的工作原理]]
借助AOT对模板预发编译时的优化,可以减少 步骤1 [[#^d5ad8a]]的开销。这是大部分“采用模板语法描述UI”的前端框架都会进行的优化,例如Vue3、Angular、Svelte。其本质原因在于模板语法是固定的,固定意味着可分析,可分析意味着在编译时可以标记模板语法中的静态部分(不变的部分)与动态部分(包含自变量,可变的部分),使 步骤1 [[#^d5ad8a]]在寻找“变化的UI”是可以跳过静态部分。Svelte、Solid.js 甚至利用AOT在编译时直接建立“自变量与UI中动态部分的关系”,在运行时,自变量发生变化后,可直接执行 步骤2 [[#^714c1d]]。
"采用JSX描述UI"的前端框架很难从AOT中受益。因为JSX是ES的语法糖,ES语句的灵活性使其很难进行静态分析。这里有两个思路来实现“使用JSX描述UI”的前端框框架在AOT中受益:
- 使用新的AOT实现。
- 约束JSX的灵活性。
React尝试过第一种思路。prepack是Meta推出的一款React编译器,用于实现AOT优化,其思路是:在保持运行结果一致的情况下,改变源代码的运行逻辑,输出性能更高的代码。即“代码在编译时将计算结果保留在编译后的代码中,而不是在运行时才去求值”。比如,如下代码:
已複製!(function () { function hello() { return "hello"; } function world() { return "world"; } global.s = hello() + " " + world(); })(); // 经过prepack编译后输出: (function () { var _$0 = this; _$0.s = "hello world"; }).call(this);
遗憾的是,由于多方面的考虑,prepack项目与2019年暂停,不过目前还能使用。
除prepack外,在React Conf2021中,Meta的工程师黄玄介绍了React Forget,这是一个可以自动生成等效于useMemo与useCallback代码的编译器,React Forget目前正处于重写后的迭代阶段。Solid.js同样使用JSX描述UI,它实现了几个内置组件用于"在UI中描述逻辑",从而减少JSX的灵活性,使AOT成为可能。
比如以下代码:
已複製!// For替代数组的map方法 <For each={state.list} fallback={<div>Loading...</div>}> {(item) => <div>{item}</div>} </For> // 用 Show 组件替换条件判断语句 <Show when={state.count > 0} fallback={<div>Loading...</div>}> <div>My Content</div> </Show> // 用 Switch 和 Match 替换 switch-case 语句 <Switch fallback={<div>Not Found</div>}> <Match when={state.route === "home"}> <Home /> </Match> <Match when={state.route === "settings"}> <Settings /> </Match> </Switch>
综上所述,前端框架可以从AOT中获得许多益处,其中对框架工作原理影响较大的是:减少
根据自变量变化计算出UI变化这一步骤的工作量。但是在框架中使用AOT的前提是代码是可以分析的,像Vue、Angular都使用了模板语法,在编译阶段就能分析出哪些是静态部分,而对于像React这种使用JSX的框架来说因为ES本身语法过于灵活导致许多组件代码需要等到实际运行时才能知道结果,自然就不太适合AOT进行优化,只能另辟蹊径。